
5月16日,在杭州举办的具身智能前沿沙龙上,浙江大学"百人计划"研究员、浙江省高层次青年人才陈昊带来了题为《如何走出具身智能的规模法则》的重磅演讲。作为法喜设计的参会观察,这场演讲不仅揭示了具身智能领域的关键技术路径分歧,更让我们看到了AI内容创作与具身智能之间的深层交叉可能。

世界模型:表征优先,而非像素生成
陈昊开篇即点明核心立场:具身智能的世界模型构建,表征学习应当优先于像素生成。这一判断直击当前行业痛点——大量研究资源投入在视觉重建的精细度上,却忽视了机器人真正需要的,是对物理世界结构和因果关系的抽象理解。这与法喜设计在AIGC内容生产中的体悟高度一致:生成一幅漂亮图像只是起点,理解图像背后的结构逻辑,才是从"模仿"走向"创造"的关键跃迁。

从LLM进化看机器人规划的路径选择
陈昊以大语言模型的进化轨迹为镜,精准剖析了机器人规划的两条路线。2020年GPT-3开启大规模预训练,实现了海量知识涌现;2022年InstructGPT引入SFT监督微调,让模型对齐人类指令,完成了"模仿"阶段;2024年o1/R1引入RLVR强化学习,原生推理能力涌现,彻底超越了单纯模仿范式。
由此,他对比了机器人规划的两种路径:当前主流路线类比SFT——VLM预训练后直接走VLA端到端,本质仍是模仿学习;而他的判断是类比原生推理——VLM预训练后跳过单纯模仿,直接走RLVR后训练,向具备原生推理能力的高阶形态进化。这一判断的核心逻辑在于:模仿永远有天花板,推理才能打开新世界。

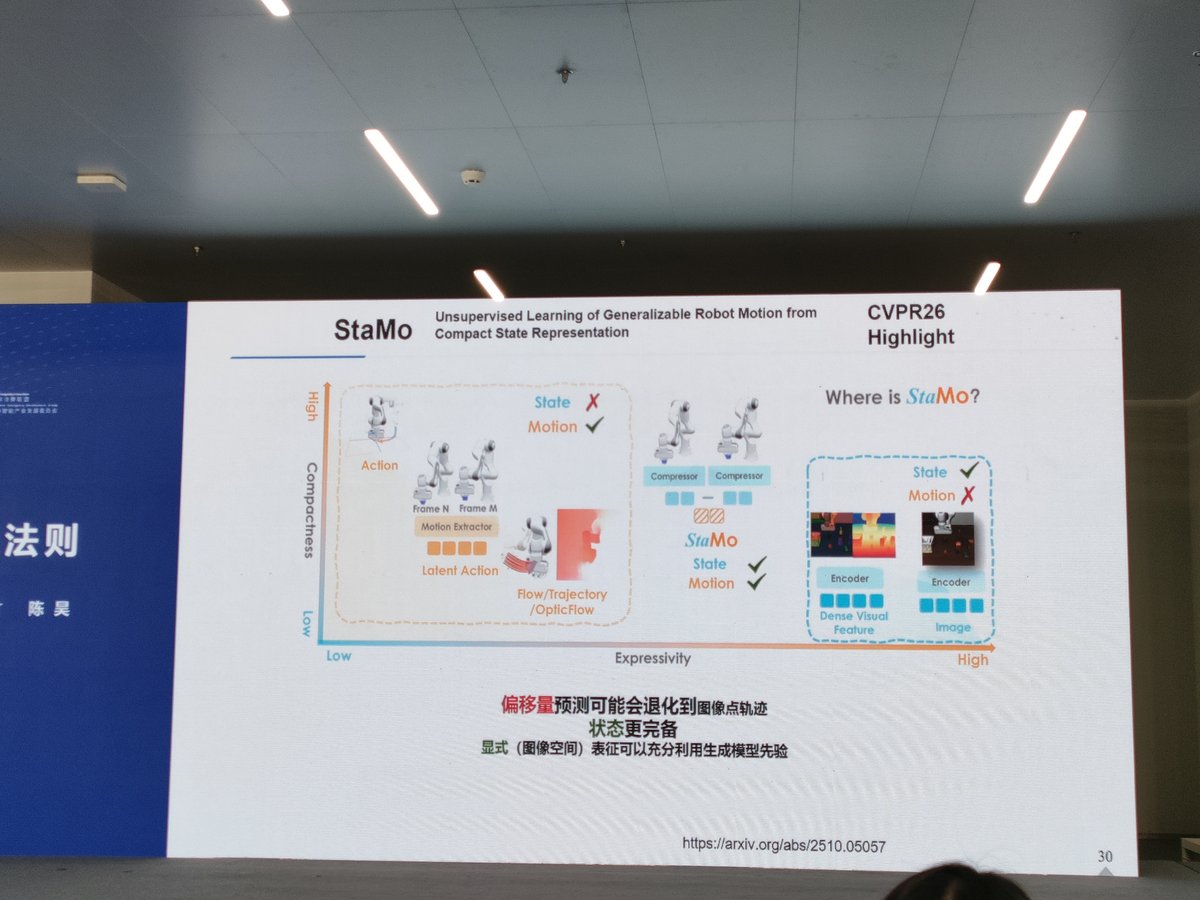
三条表征路径:JEPA受限、π0.6部分可行、StaMo更优解
陈昊进一步展示了三条表征学习路径的对比:JEPA路径受到表征能力的根本性限制;π0.6的RL Token路径部分可行但仍有不足;而他们提出的StaMo方案则展现出更优的架构设计。
StaMo的核心突破在于:仅用两个Token即可实现完全自洽的世界表征,同时支持图像重建与动作的自然涌现,且整个过程完全无监督学习。这意味着模型无需依赖海量标注数据,就能从感知到行动建立完整的认知闭环。该方案已入选CVPR 2026 Highlight(论文链接:arxiv.org/abs/2510.05057),是具身智能表征学习领域的前沿成果。
RLVR为什么能赢?
陈昊给出了RLVR胜出的三大理由:第一,完整继承VLM的世界知识与原生推理能力,保留泛化性;第二,Reward信号可灵活设计,无需依赖海量人类演示数据,数据效率更高;第三,支持对分布外(OOD)场景的有效外推,这是模仿学习永远无法企及的能力边界。在法喜设计看来,这与AIGC内容生产的逻辑异曲同工——单纯模仿已有风格终有尽头,只有建立起"理解-推理-创造"的闭环,才能持续产出有生命力的原创内容。

已验证的起点,未突破的瓶颈
陈昊坦诚地划分了当前技术的边界:语言Token预测涌现了知识推理能力,图像生成验证了感知泛化——但这些只是"意图理解+粗粒度规划"的起点。真正未突破的核心瓶颈在于视频的精确结构理解,以及物理与运动的规模法则——高质量复杂操作数据的严重匮乏,制约了从"理解"到"执行"的跨越。
关键结论:想要实现精确的物理世界结构理解与复杂动作执行,无法通过简单的参数堆叠解决,必须寻求属于具身智能自身的独立技术方案。这一判断对整个行业具有警示意义——规模不是万能药,架构创新才是破局关键。

从本体适配到场景交付:八大核心能力栈
演讲最后,陈昊展示了从本体适配到场景交付的完整能力栈,涵盖八大核心能力:本体适配(底盘、机械臂、夹爪、传感器、控制器)、ROS/ROS2系统、视觉感知二开、导航与运动控制、机械臂与末端开发、场景任务二开、多机器人协同、仿真测试与验收。这一完整的技术栈展示,印证了具身智能从实验室走向产业落地的系统性工程思维。
作为深耕AI内容创作的品牌设计机构,法喜设计在这场演讲中看到了具身智能与内容创作的深层共鸣:无论是AI漫剧IP开发中的角色一致性推理,还是AIGC内容生产中的风格涌现,都需要跳出单纯模仿,走向"理解-推理-创造"的原生智能范式。具身智能的规模法则,或许正是内容智能下一步进化的镜像。
【能力标签】
品牌视觉设计 | AIGC内容生产 | AI漫剧IP开发
【联系方式】
服务热线:400-888-4860
官方网站:https://www.faxide.com
【免责声明】
本方案版权归杭州法喜品牌设计有限公司所有。方案中展示的图片为AI生成的创意参考,方案整体为策划方向探讨,不代表最终实际交付成果。

